Language Fusion for Parameter-Efficient Cross-lingual Transfer
 GitHub
GitHub
TL;DR:
- FLARE fuses knowledge from both source language (English) and target language representations inside parameter-efficient adapters.
- Enables multilingual LLMs to perform better at natural language understanding (NLU) in low-resource languages, while remaining resource-efficient.
- No extra parameters or compute overhead, just clever adapter wiring and translation.
Motivation
Multilingual language models like Llama 3 and Gemma 2 are still trained almost entirely on English data, Llama 3’s pretraining is only about 5% multilingual
This imbalance results in a much stronger English representation space. Ideally, a cross-lingual transfer method can tap into these strong English representations when adapting to new (target) languages.
Meet FLARE: Fusion for Language Representations!
FLARE an effective method that enables multilingual LLMs to use both source (e.g., English) and target language knowledge to improve NLU performance.
It’s also lightweight: FLARE doesn’t add any additional parameters to the model.
Cross-lingual Transfer: How it Works
We start with a multilingual LLM and assume we have labeled data in the source language (let’s use English as our example).
First, we fine-tune the model on English task data using supervised learning.
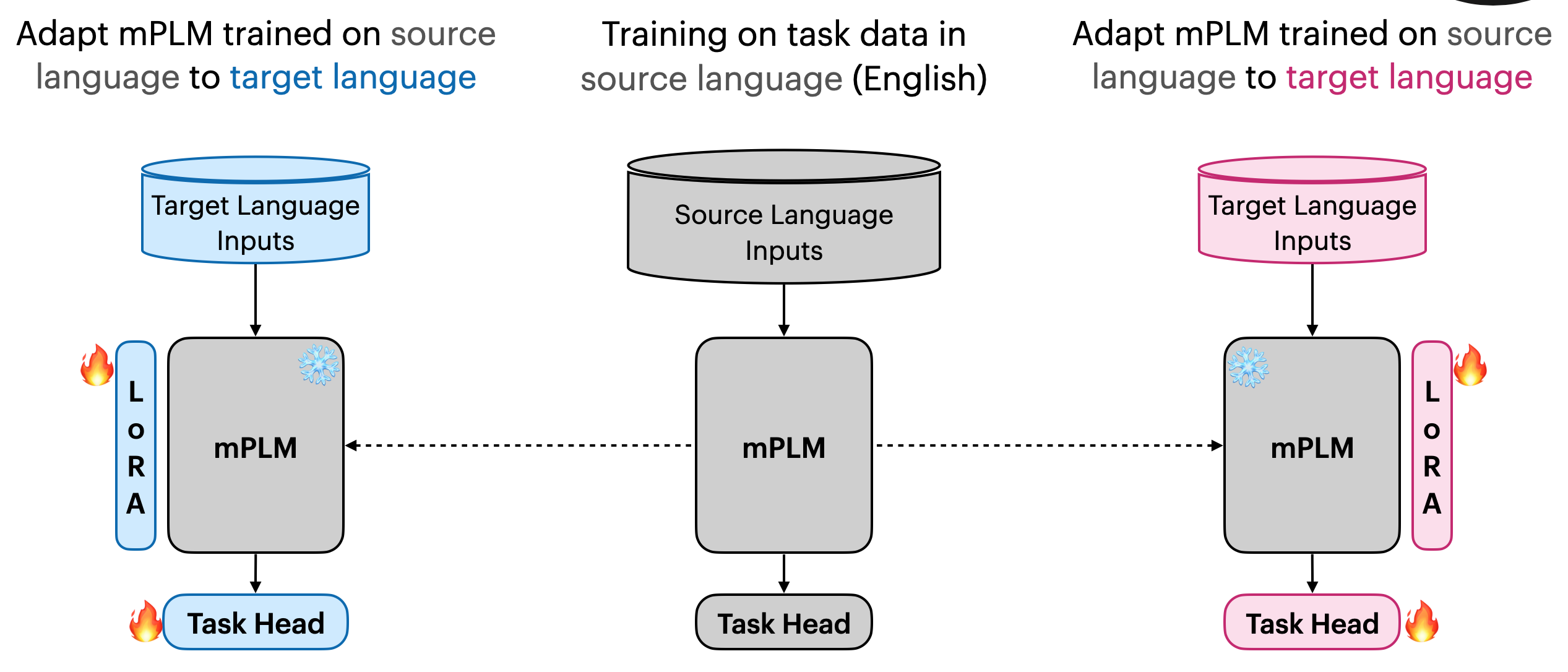
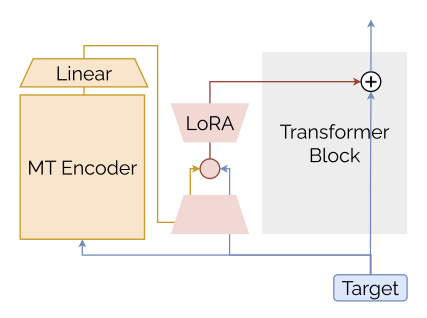
The FLARE Approach
To adapt to the target language, we use LoRA adapters inserted into the transformer’s attention modules, leaving the original model weights frozen.
Because labeled data in the target language is scarce, we machine-translate the English training set using NLLB 3.3B.
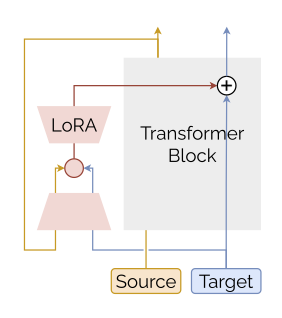
FLARE takes both the source and translated target text as input. For each forward pass, it does the following:
- Runs a forward pass on the source language input to get strong English representations, which are fed into the LoRA adapter.
- Processes the translated target language input in the regular forward pass, with target language representations also passed through the adapter.
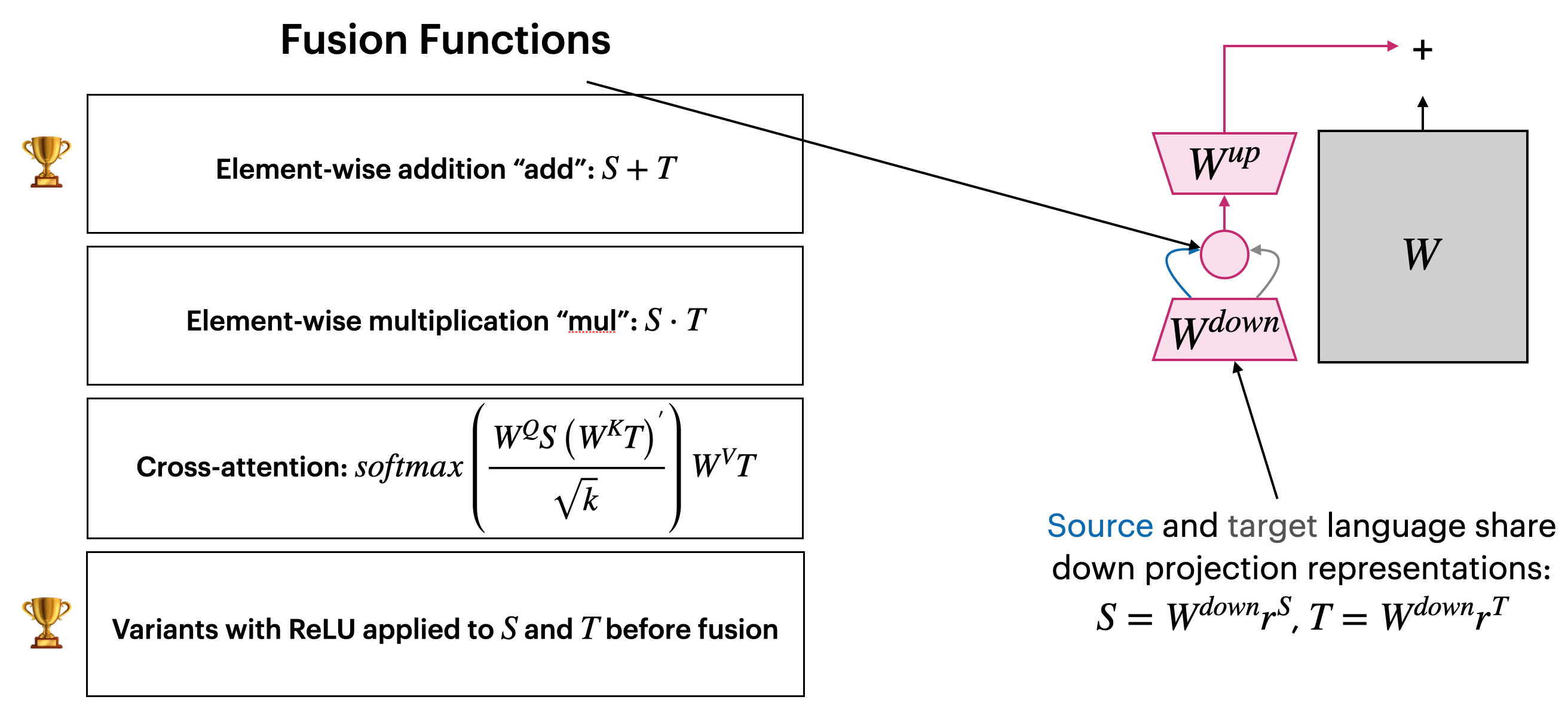
- Within the adapter bottleneck, FLARE merges the source and target representations. This fused representation continues up to the next transformer layer.
- The process repeats for all layers.
FLARE-MT: Making It Even More Efficient
The FLARE-MT variant skips the full forward pass on the source language input.
Instead, it generates a latent translation using just the NLLB encoder and fuses this into every transformer layer in the main model.
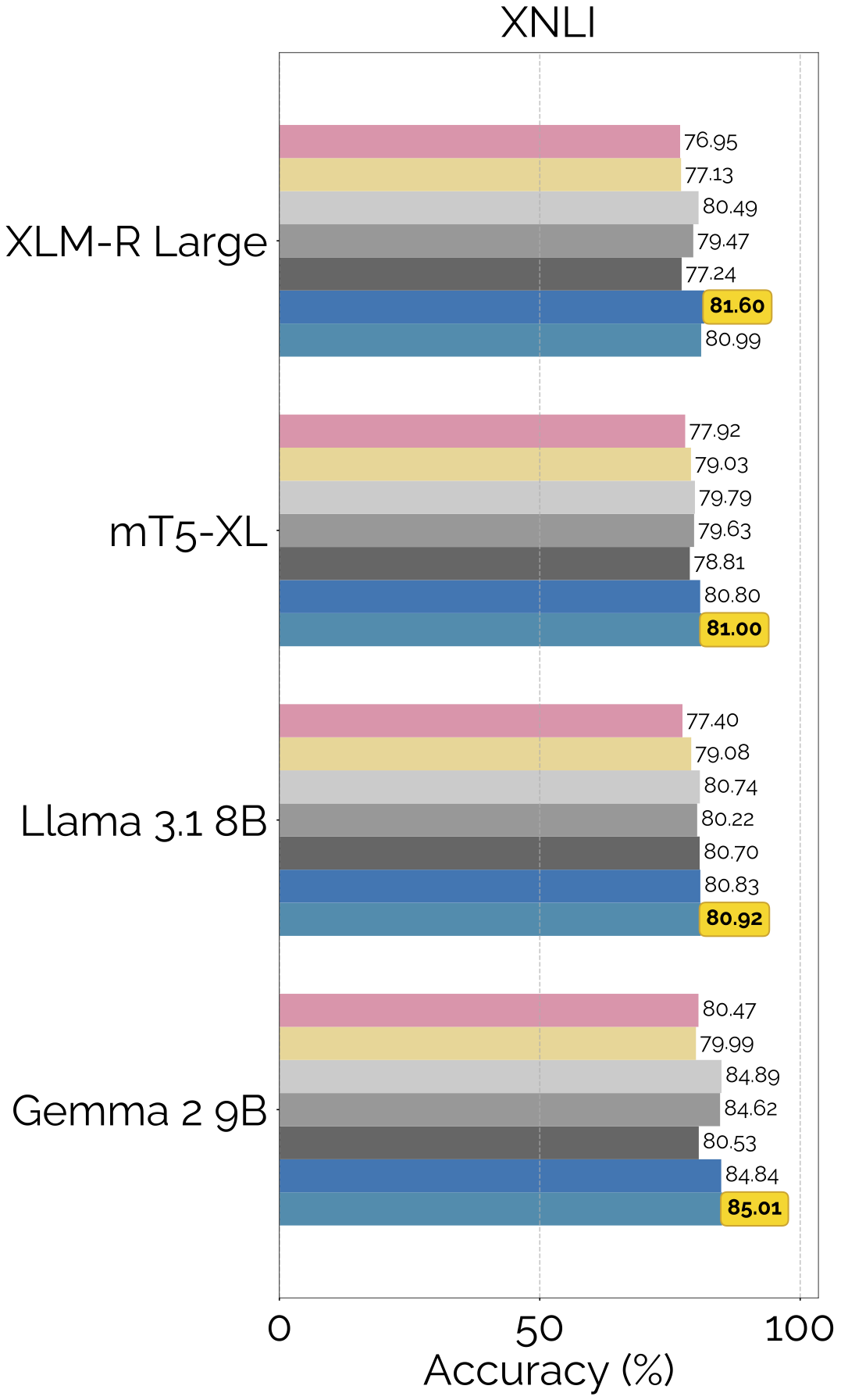
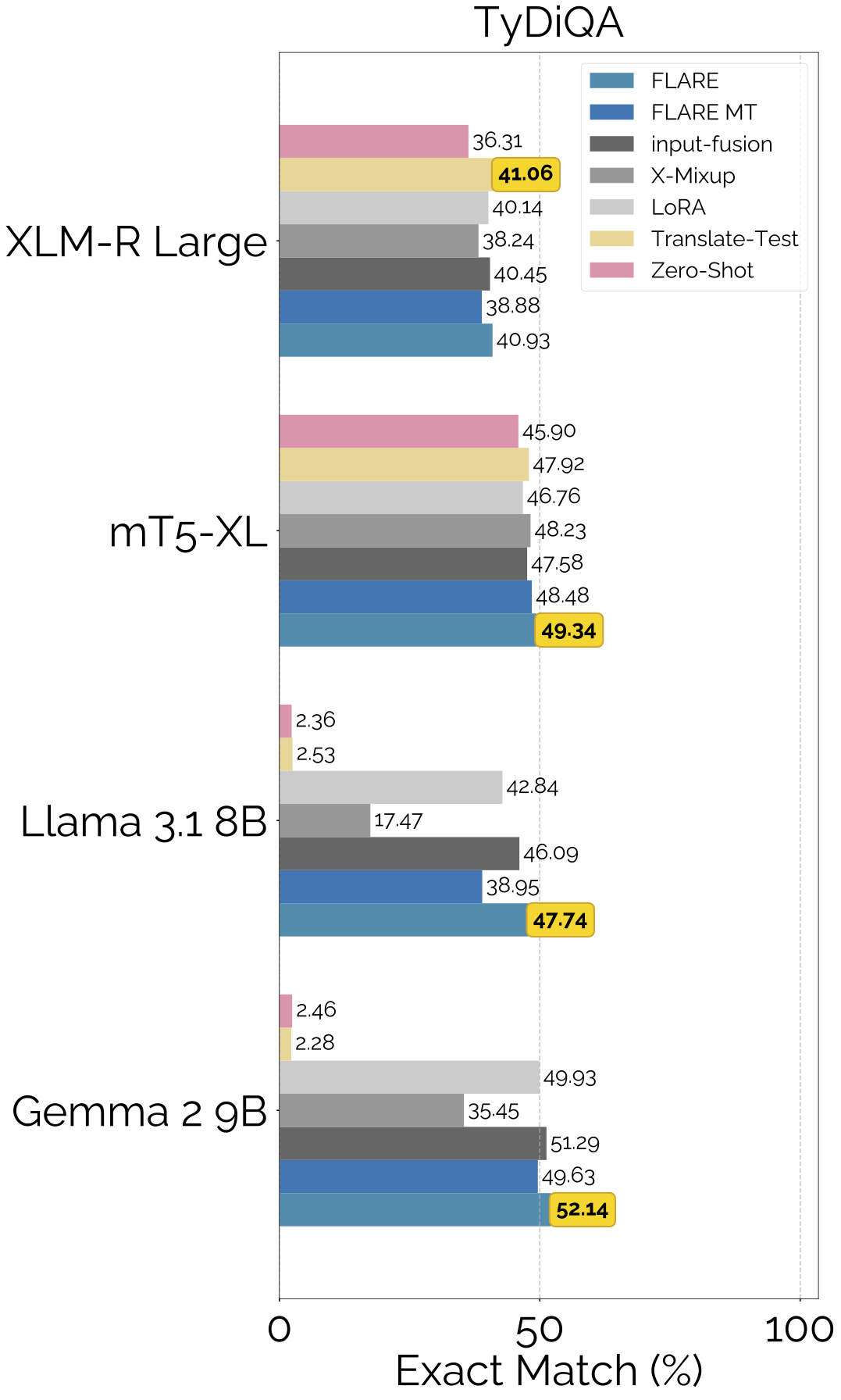
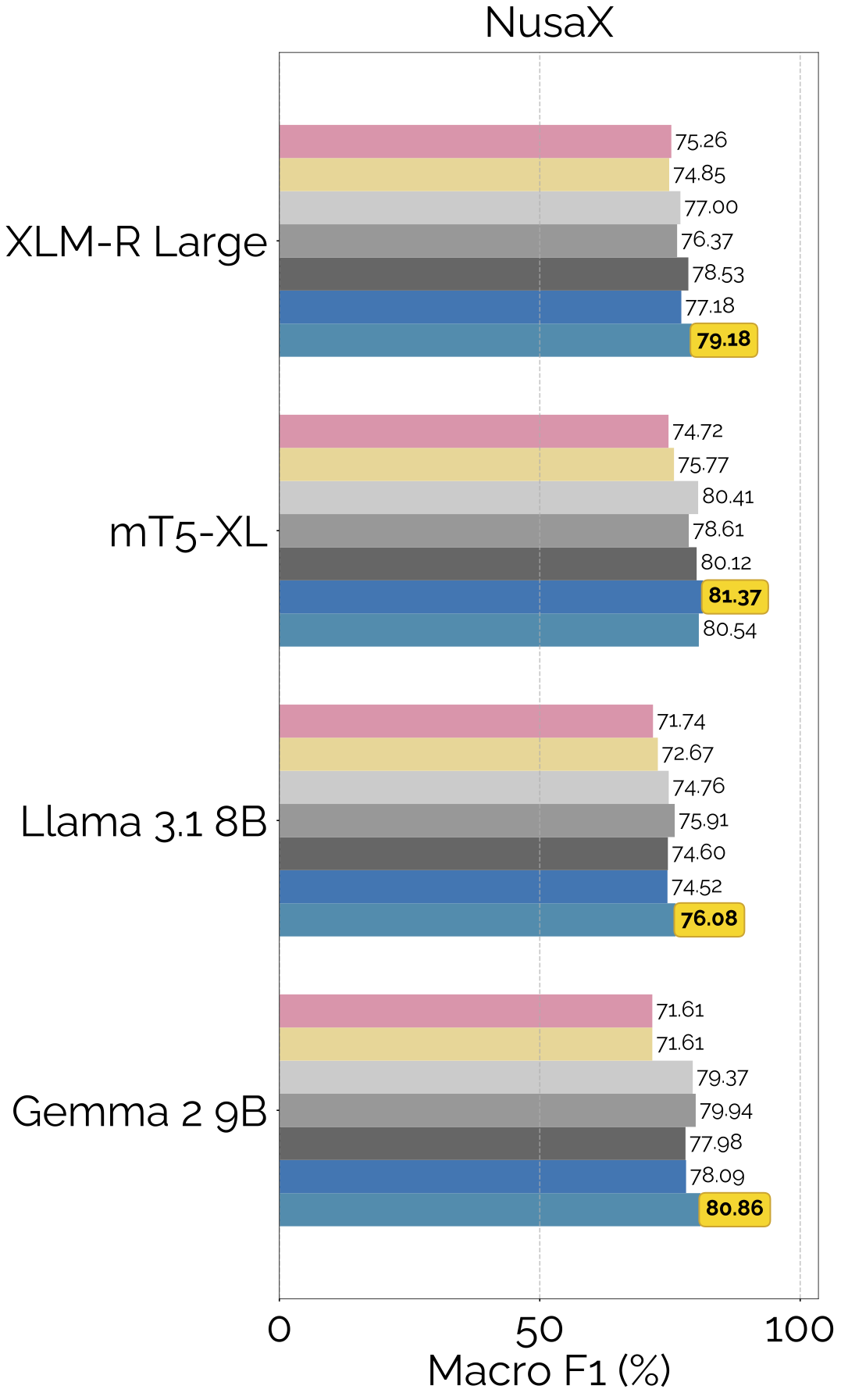
Results
FLARE is the best performing translate-train method in our experiments.
FLARE also outperforms other translate-test and zero-shot baselines:
For more details, ablation studies, and deeper analysis, check out the paper on arXiv!