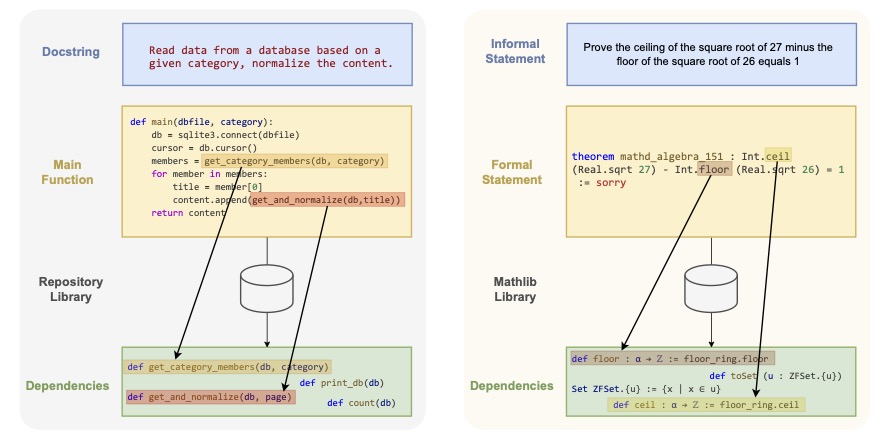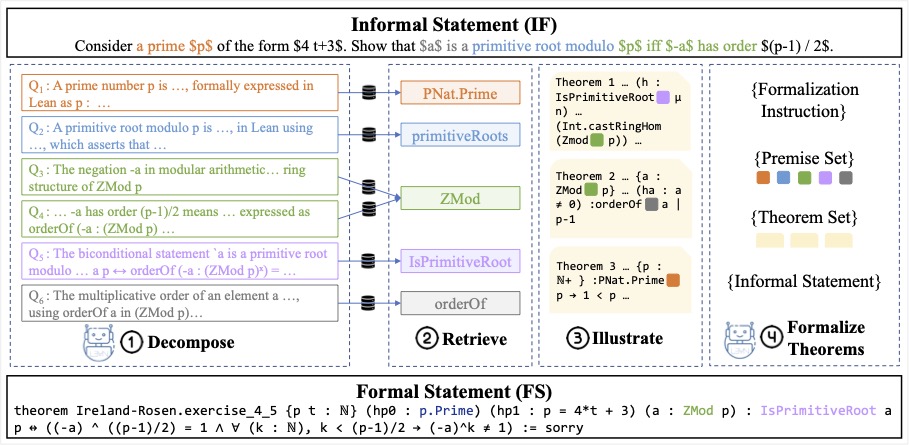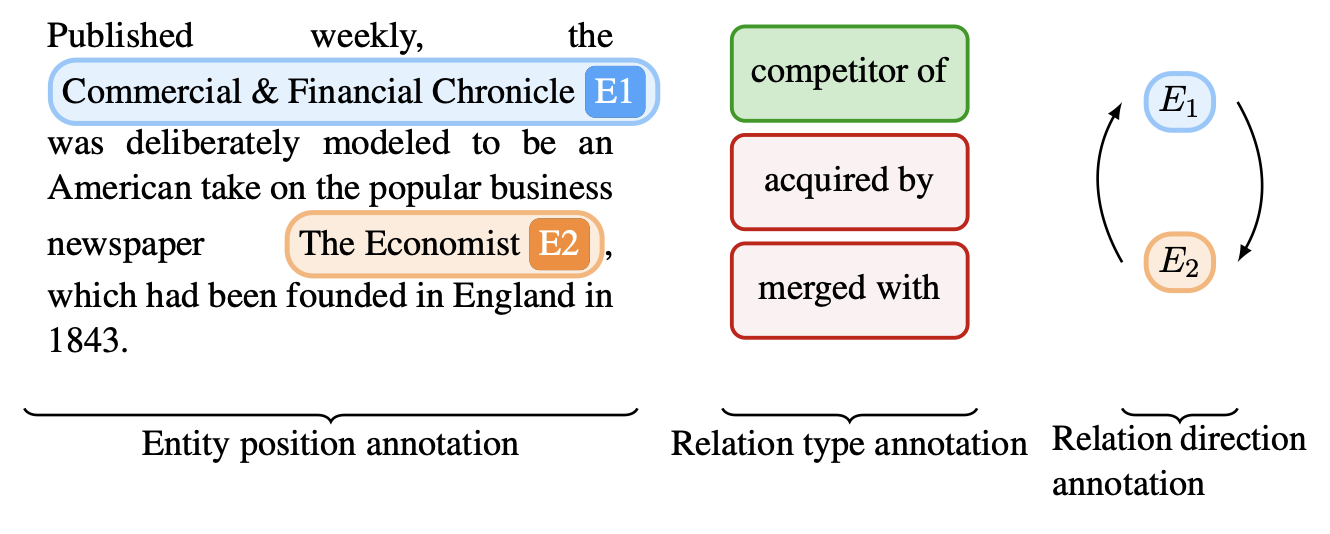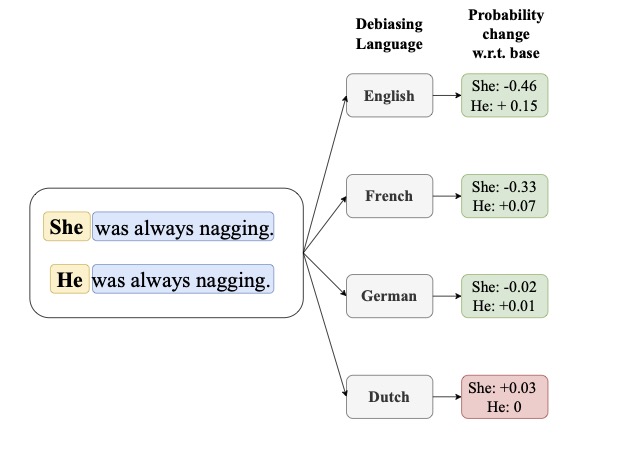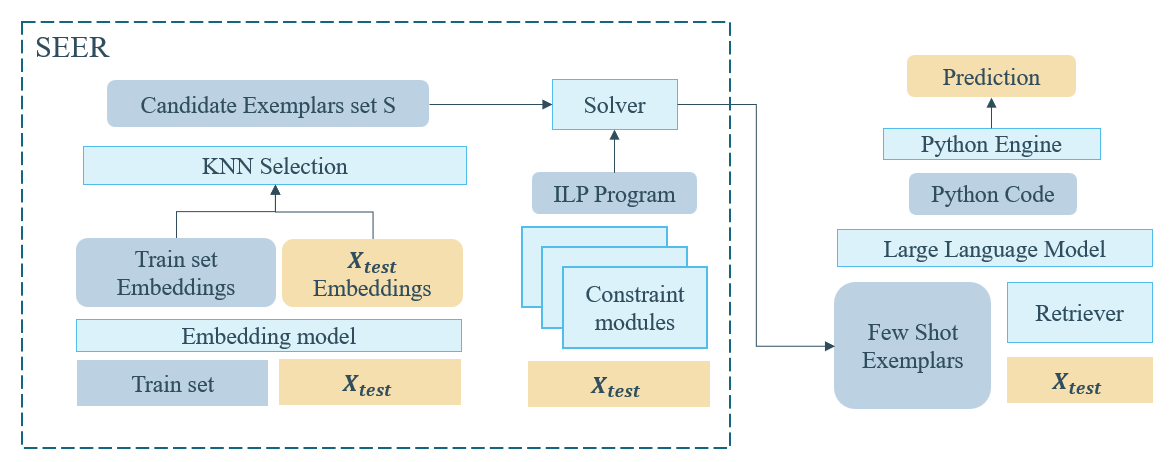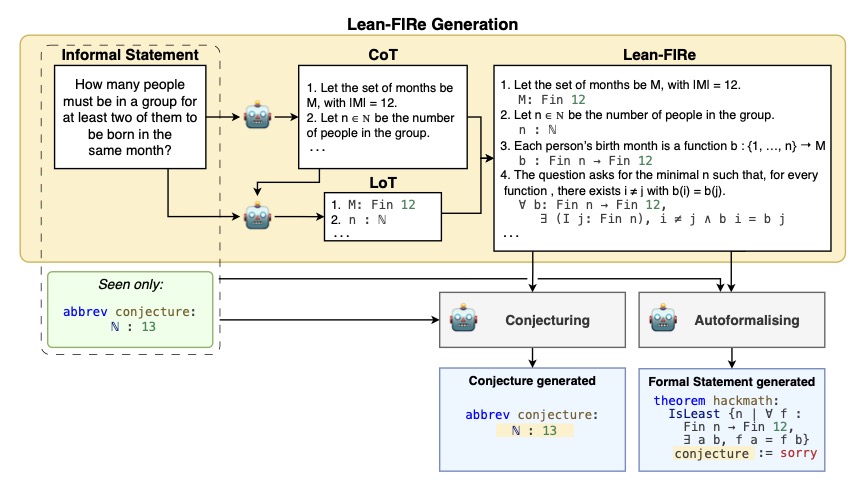
We identify conjecturing as a critical bottleneck in formal mathematical reasoning. We introduce ConjectureBench, a dataset to evaluate LLM conjecturing capabilities, and LEAN-FIRE, an inference-time method that improves autoformalisation by treating conjecturing as a distinct step.